loj#P6861. 「ICPC World Finals 2021」分流
「ICPC World Finals 2021」分流
Description
A splitstream system is an acyclic network of nodes that processes finite sequences of numbers. There are two types of nodes (illustrated in Figure J.1):
- A split node takes a sequence of numbers as input and distributes them alternatingly to its two outputs. The first number goes to output , the second to output , the third to output , the fourth to output , and so on, in this order.
- A merge node takes two sequences of numbers as input and merges them alternatingly to form its single output. The output contains the first number from input , then the first from input , then the second from input , then the second from input , and so on. If one of the input sequences is shorter than the other, then the remaining numbers from the longer sequence are simply transmitted without being merged after the shorter sequence has been exhausted.
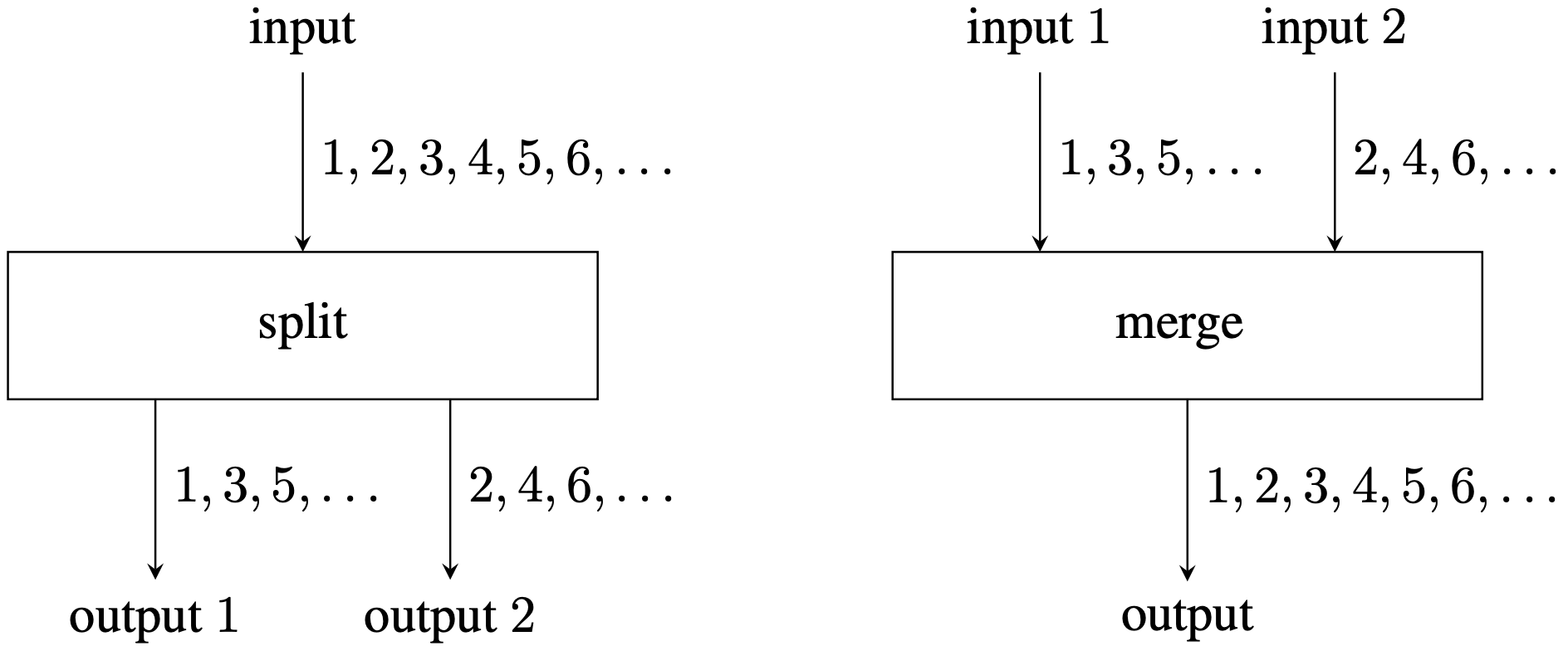
The overall network has one input, which is the sequence of positive integers . Any output of any node can be queried. A query will seek to identify the number in the sequence of numbers for a given output and a given . Your task is to implement such queries efficiently.
Input
The first line of input contains three integers , , and , where () is the length of the input sequence, () is the number of nodes, and () is the number of queries.
The next lines describe the network, one node per line. A split node has the format , where , and identify its input, first output and second output, respectively. A merge node has the format , where , and identify its first input, second input and output, respectively. Identifiers , and are distinct positive integers. The overall input is identified by , and the remaining input/output identifiers form a consecutive sequence beginning at . Every input identifier except appears as exactly one output. Every output identifier appears as the input of at most one node.
Each of the next lines describes a query. Each query consists of two integers and , where () is a valid output identifier and () is the index of the desired number in that sequence. Indexing in a sequence starts with .
Output
For each query and output one line with the number in the output sequence identified by , or none if there is no element with that index number.
200 2 2
S 1 2 3
M 3 2 4
4 99
4 100
100
99
100 3 6
S 1 4 2
S 2 3 5
M 3 4 6
6 48
6 49
6 50
6 51
6 52
5 25
47
98
49
51
53
100
2 3 3
S 1 2 3
S 3 4 5
M 5 2 6
3 1
5 1
6 2
2
none
none